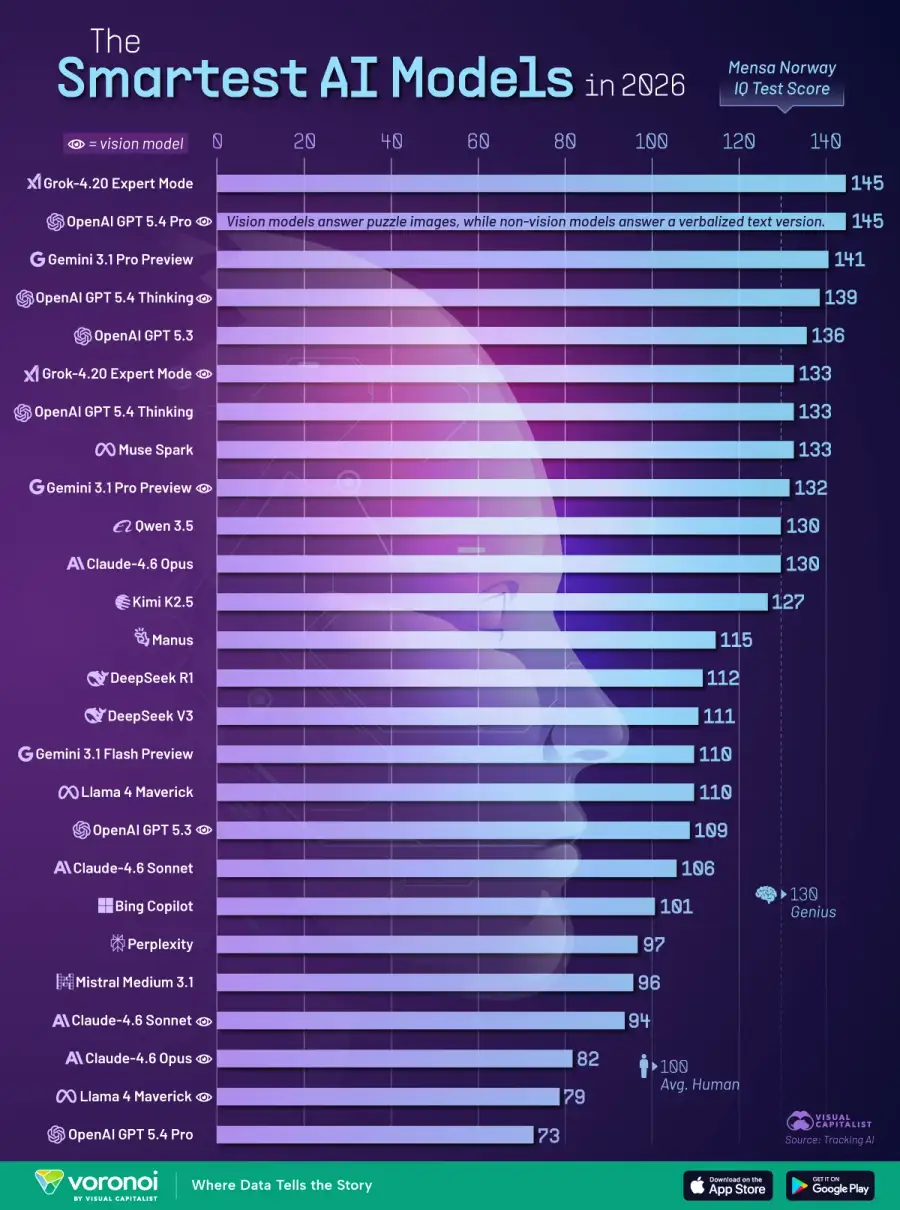
يتزايد التنافس على بناء نماذج ذكاء اصطناعي أكثر ذكاءً في القمة.
هذا التصور، وه جزء من اسبوع الذكاء الاصطناعي الذي تنظمه Visual Capitalist برعاية Terzo، يصنف الأنظمة الرائدة باستخدام بيانات من TrackingAI، التي تقيس أداء النماذج بناءً على اختبار Mensa Norway IQ اعتبارًا من أبريل 2026.
تُظهر النتائج من يتصدر اليوم ومدى ضآلة الفارق بين المتنافسين الرئيسيين، مع تجمع نماذج حدودية متعددة بالقرب من قمة لوحة المتصدرين.
تعادل في الصدارة
يقدم التصنيف لمحة سريعة عن أداء نماذج الذكاء الاصطناعي الرائدة اليوم في مهام التعرف على الأنماط المجردة، ومدى تقارب المنافسة.
كما يوضح الجدول أدناه، فإن فجوة صغيرة فقط تفصل الآن بين أفضل الطرازات:
معدل الذكاء في مينسا النرويج (أبريل 2026)
وضع الخبير في Grok-4.20
145
OpenAI GPT 5.4 Pro (الرؤية)
145
معاينة Gemini 3.1 Pro
141
OpenAI GPT 5.4 التفكير (الرؤية)
139
OpenAI GPT 5.3
136
Grok-4.20 وضع الخبير (الرؤية)
133
OpenAI GPT 5.4 Thinking
133
ميتا ميوز سبارك
133
معاينة Gemini 3.1 Pro (رؤية)
132
كوين 3.5
130
كلود-4.6 أوبوس
130
كيمي كيه 2.5
127
مانوس
115
ديب سيك آر 1
112
ديب سيك الإصدار الثالث
111
أبرز ما يُلاحظ هو مدى تقارب المراكز الأولى في قائمة المتصدرين. يتشارك كل من Grok-4.20 Expert Mode و OpenAI المركز الأول برصيد 5.4 GPT 145 نقطة، بينما يليهما Gemini 3.1 Pro Preview مباشرةً برصيد 141 نقطة .
يشير هذا التباين الضيق إلى أن نماذج الذكاء الاصطناعي الرائدة تتقارب بشكل متزايد في القمة، حيث يمكن أن يؤدي اختلاف بضع نقاط فقط إلى تغيير التصنيفات.
كما أن المكاسب التي تحققت منذ عام 2025 جديرة بالملاحظة. فقد بلغ أعلى مستوى في العام الماضي 135، مقارنةً بـ 145 في نتائج هذا العام، مما يسلط الضوء على سرعة تحسن النماذج الرائدة في هذا المعيار.
لا تواكب جميع النماذج التطورات. فمن بين كبار مطوري الذكاء الاصطناعي، يحتل نموذج ميسترال المرتبة الأدنى في هذه المجموعة من البيانات، حيث سجل 97 نقطة ، وهو أقل بكثير من المجموعة الرائدة.
كيف تُجري TrackingAI الاختبار
تستخدم منصة TrackingAI اختبار Mensa Norway العام، وهو عبارة عن مجموعة من 35 لغزًا بصريًا. بالنسبة للنماذج غير البصرية، تُطرح الأسئلة شفهيًا، بينما تتلقى النماذج البصرية الصور الأصلية مباشرةً.
لذا، يُفضّل فهم هذه النتائج كمعيار للمقارنة، وليس كمقياس نهائي للذكاء العام. ولأن الاختبار يعتمد أساسًا على الجانب البصري، فقد تختلف نتائج النماذج تبعًا لطريقة عرض الأسئلة.
لماذا يُعد هذا المعيار مهمًا؟
تُعدّ لوحة المتصدرين في TrackingAI مفيدة لأنها توفر طريقة بسيطة ومألوفة لمقارنة أداء الاستدلال بمرور الوقت. ويشير الموقع أيضًا إلى أنه في حال رفض النموذج الإجابة، يُطرح عليه السؤال نفسه حتى 10 مرات، وتُستخدم أحدث إجابة في حساب النتيجة.
مع ذلك، فإنّ معيار قياس الذكاء لا يغطي سوى جانب واحد من القدرات. فهو لا يقيس كل ما يهم في استخدام الذكاء الاصطناعي في العالم الحقيقي، مثل القدرة على البرمجة، والموثوقية في المعلومات، واستخدام الأدوات، أو الأداء في المجالات المهنية.






