إن أهم سباق تكنولوجي في تاريخ الحضارة جارٍ على قدم وساق.
تستثمر الشركات الرائدة في العالم مئات المليارات من الدولارات سعياً وراء هدف واحد: الذكاء الاصطناعي الذي يضاهي الذكاء البشري.
لم ينجح أحد حتى الآن. لا Google، ولا OpenAI، ولا Anthropic.
حتى يومنا هذا، في الكون المعروف، لا يوجد سوى مثال واحد لنظام قادر على الذكاء العام. هذا النظام هو الدماغ البشري.
من المثير للدهشة إذن مدى ضآلة فهمنا لكيفية عمل الدماغ البشري.
والأكثر إثارة للدهشة -بل والمثير للسخرية- هو قلة استثمارنا في تطوير هذا الفهم.
إن إجمالي الموارد التي تخصصها البشرية لفهم الدماغ ضئيلة بشكل غير متناسب، بل تكاد تكون مثيرة للسخرية، مقارنة بالموارد التي تُنفق على توسيع نطاق نموذج الذكاء الاصطناعي السائد اليوم.
في عام 2025، أنفقت أربع شركات فقط - Alphabet، وAmazon، وMeta، وMicrosoft - ما يقارب 400 مليار دولار على البنية التحتية للذكاء الاصطناعي: مراكز البيانات، والرقائق الإلكترونية، والطاقة اللازمة لتدريب وتشغيل نماذج الذكاء الاصطناعي المتطورة.
هذا العام، سيرتفع هذا الرقم إلى أكثر من 600 مليار دولار. وبحلول عام 2030، تتوقع McKinsey أن تستثمر البشرية مبلغًا هائلًا قدره 6.7 تريليون دولار لبناء مراكز بيانات الذكاء الاصطناعي.
دعونا نقارن هذه الأرقام بأهم جهود البحث في مجال الدماغ في العام الماضي.
في عام 2025، أطلقت منظمة Asteraغير الربحية واحدة من أكثر مبادرات أبحاث الدماغ تمويلاً في التاريخ، بقيادة عالمة الأعصاب البارزة دوريس تساو.
وقد تصدر البرنامج الجديد عناوين الأخبار نظراً لحجم الاستثمار غير المسبوق.
كما كتب Astera عن هذا الجهد: "نسعى إلى فهم أحد أعمق ألغاز العلم: كيف ينتج الدماغ التجربة الواعية والإدراك والسلوك الذكي ... إن الكشف عن هذه المبادئ من شأنه أن يحول كلاً من علم الأعصاب والتكنولوجيا - الكشف عن الآلية المسؤولة عن توليد التجربة الواعية، وفي الوقت نفسه، توفير إطار عمل جديد للذكاء الاصطناعي العام."
حجم برنامج Astera؟ 600 مليون دولار على مدى 10 سنوات.
هذا أقل بأربعة أضعاف - أي عشرة آلاف مرة - من الاستثمار السنوي الذي ستنفقه بضع شركات فقط على مراكز بيانات الذكاء الاصطناعي هذا العام.
تُعدّ مبادرة " BRAIN " (BRAIN Initiative) التابعة للحكومة الأمريكية، والتي انطلقت عام 2014، أكبر مبادرة على الإطلاق لفهم الدماغ البشري.
وقد بلغ إجمالي الاستثمار في هذه المبادرة، على مدار أكثر من عقد، 3 مليارات دولار فقط. وفي عام 2023، وهو العام الذي شهد أعلى تمويل لها، و
صل حجم الاستثمار إلى 680 مليون دولار.
إن حجم هذه الأرقام كبير بشكل صارخ. وهذا يدل على سوء تخصيص خطير للموارد على مستوى المجتمع، ولكنه يمثل أيضاً فرصة هائلة.
قلما يوجد في عالمنا اليوم ما هو أثمن أو أكثر طلباً من فهم طبيعة الذكاء فهماً أعمق. ففي نهاية المطاف، هذا السعي - لفهم الذكاء فهماً أفضل بهدف ابتكار نسخ رقمية منه واستثمارها - هو ما يحفز في نهاية المطاف ضخ تريليونات الدولارات في البنية التحتية للذكاء الاصطناعي.
وهذا السعي هو ما جعل شركة Nvidia أغلى شركة في العالم، وهو ما يدفع شركتي OpenAI وAnthropic بسرعة إلى تقييمات تريليونية الدولارات.
ماذا لو كانت الطريقة الأكثر فعالية والأكثر تأثيراً لتعزيز فهمنا لطبيعة الذكاء - وبالتالي قدرتنا على تطوير نسخ اصطناعية قوية منه - ليست من خلال تخصيص تريليونات الدولارات وكل الطاقة والحوسبة في العالم لتوسيع نطاق نموذج الذكاء الاصطناعي الحالي (الذي من الواضح أنه غير كامل)، بل من خلال فهم أفضل، انطلاقاً من المبادئ الأساسية، لنقطة الدليل الفعلية الوحيدة التي لدينا على وجود نظام ذكي بشكل عام: الدماغ البشري؟
تبدو هذه أطروحة منطقية، بل وبديهية، تستحق المتابعة. ولكن بالنظر إلى الطريقة التي تُخصص بها البشرية مواردها اليوم، فإنها تبقى وجهة نظر لا تحظى بإجماع واسع.
كيف يُمكن، تحديداً، تعزيز مساعينا في مجال الذكاء الاصطناعي من خلال فهم أفضل للدماغ البشري؟
ما الذي يستطيع الدماغ فعله ولا تستطيع أنظمة الذكاء الاصطناعي الحديثة فعله حتى الآن؟
هناك العديد من الإجابات على هذا السؤال، ولكن دعونا نركز على ثلاثة منها.
1.التعلم المستمر
الجواب الأول هو القدرة على التعلم المستمر من التجربة. هذا شيء يفعله البشر بسهولة تامة، بينما لا يزال الذكاء الاصطناعي الحالي عاجزاً عنه تماماً.
يتعلم البشر حقائق جديدة، ويكتسبون مهارات جديدة، ويتعرفون على أشخاص جدد، ويتعرفون على أماكن جديدة بشكل مستمر طوال حياتهم.
تتغير أدمغتنا في كل لحظة من كل يوم مع تعرضنا لتجارب ومعارف جديدة.
تُعرف هذه القدرة بالمرونة العصبية: قدرة الدماغ على إعادة تنظيم نفسه من خلال تكوين روابط عصبية جديدة طوال الحياة.
رغم الجهود المبذولة على مدى عقود، ما زلنا عاجزين عن بناء شبكات عصبية اصطناعية بهذه القدرة.
ولا يزال الذكاء الاصطناعي الحالي غير قادر على التعلم المستمر .
بدلاً من ذلك، تتضمن طريقة بناء أنظمة الذكاء الاصطناعي اليوم مرحلتين متميزتين: التدريب والاستدلال.
خلال مرحلة التدريب، يُعرض على نموذج الذكاء الاصطناعي مجموعة من البيانات التي يتعلم منها عن العالم.
ثم، خلال مرحلة الاستدلال، يُفعّل النموذج: حيث يُنتج مخرجات ويُنجز مهامًا بناءً على ما تعلمه خلال التدريب.
تتم عملية تعلم الذكاء الاصطناعي بالكامل خلال مرحلة التدريب. بعد اكتمال التدريب، تصبح أوزان نموذج الذكاء الاصطناعي ثابتة.
ورغم تعرض الذكاء الاصطناعي لأنواع مختلفة من البيانات والخبرات الجديدة عند نشره في العالم الحقيقي، إلا أنه لا يتعلم من هذه البيانات الجديدة.
يمكن أن تساعد الحلول البديلة المختلفة في تعويض عدم قدرة الذكاء الاصطناعي على التعلم باستمرار - من بينها التعلم في السياق، والضبط الدقيق المتكرر، والتوليد المعزز بالاسترجاع المقترن بالذاكرة الخارجية - ولكن لا يوجد حل كامل للمشكلة.
كل محاولة لبناء ذكاء اصطناعي يمكنه التعلم باستمرار - والذي يمكنه تحديث أوزانه بشكل مستمر، بالطريقة التي تفعلها أدمغة البشر - قد واجهت نفس التحدي الأساسي: النسيان الكارثي.
باختصار، يشير النسيان الكارثي إلى ميل الشبكات العصبية الاصطناعية إلى الكتابة فوق المعرفة القديمة وفقدانها عند إضافة معرفة جديدة.
تخيل نموذج ذكاء اصطناعي تم تحسين أوزانه لإنجاز المهمة (أ)
ثم يُعرَّض لبيانات جديدة متعلقة بإنجاز المهمة (ب).
الفرضية الأساسية للتعلم المستمر هي أن أوزان النموذج يمكن تحديثها ديناميكيًا لتعلم حل المهمة (ب).
ولكن بتحديث الأوزان لإنجاز المهمة (ب)، تتدهور قدرة النموذج على إنجاز المهمة (أ) حتمًا.
لا يعاني البشر من النسيان الكارثي. فتعلم قيادة السيارة، على سبيل المثال، لا يجعلنا ننسى كيفية لعب التنس.
كما أن تعلم تاريخ الولايات المتحدة لا يجعلنا ننسى كيفية حل مسائل الجبر. يتمكن الدماغ البشري من استيعاب المعلومات الجديدة باستمرار دون التخلي عن المعرفة الموجودة.
ما زلنا لا نفهم كيف يقوم الدماغ بذلك. لو فهمنا، لكان ذلك بمثابة مخطط لإطلاق العنان للتعلم المستمر في الذكاء الاصطناعي. وسيكون ذلك إنجازًا عظيمًا.
كتب Dwarkesh Patel، المعلق المتخصص في الذكاء الاصطناعي، العام الماضي: "عندما نتوصل إلى حل لمشكلة التعلم المستمر، سنشهد قفزة نوعية هائلة في قيمة النماذج الرائدة. قد يصبح الذكاء الاصطناعي القادر على التعلم المستمر ذكاءً خارقاً بسرعة كبيرة دون أي تقدم إضافي في الخوارزميات."
حتى فهمنا الجزئي للدماغ البشري يقدم بعض التلميحات.
نعلم أن الدماغ يمتلك نظامين مختلفين للتعلم: الحصين، وهو "متعلم سريع" يُشفّر المعلومات الجديدة بسرعة على مدار اليوم، والقشرة المخية الحديثة، وهي "متعلم بطيء" تُدمج المعلومات تدريجيًا في قاعدة معارفها طويلة الأمد.
ولأن عملية دمج المعلومات من الحصين إلى القشرة المخية الحديثة عملية مقصودة وانتقائية، فإن الدماغ قادر على إيجاد أنماط ودمج البيانات الجديدة في الأطر الموجودة دون استبدالها.
يلعب نشاط بشري عالمي ولكنه لا يزال غامضًا دورًا محوريًا في نقل المعلومات هذا من الحصين قصير المدى إلى القشرة المخية الحديثة طويلة المدى: النوم والأحلام.
ومن بين الأفكار الأخرى المستقاة من علم الأعصاب: أن البنية المعيارية والمتفرقة للدماغ البشري تلعب دورًا رئيسيًا في قدرته على التعلم بشكل مستمر.
عندما يقوم نموذج الذكاء الاصطناعي بفعل ما، يتم تنشيط جميع خلاياه العصبية. ويعود ذلك إلى أن المعرفة في الشبكة العصبية الاصطناعية موزعة بشكل شامل على جميع أوزان الشبكة.
وهذا نتيجة لخوارزمية الانتشار العكسي، وهي الخوارزمية الأساسية التي يقوم عليها الذكاء الاصطناعي الحديث، والتي تتضمن إرسال إشارة خطأ عكسيًا عبر الشبكة بأكملها وتحديث كل وزن بالتزامن مع ذلك أثناء عملية التدريب.
هذا الهيكل المترابط عالميًا يعني أن تغيير أي جزء من أوزان نموذج الذكاء الاصطناعي، حتى لو كان جزءًا صغيرًا فقط - وهو أمر مطلوب من أجل التعلم المستمر - يمكن أن يعطل قدرًا كبيرًا من معرفته، مما يؤدي إلى نسيان كارثي.
لا يُبنى الدماغ البشري على هذا النحو. فالروابط بين الخلايا العصبية فيه تتقوى أو تضعف بناءً على التفاعلات المحلية دون الاعتماد على خوارزمية شاملة أو إشارة خطأ.
ويُعدّ التعلّم الهيبي - وهو حجر الزاوية في التعلّم البيولوجي، والذي يُلخّص في عبارة "الخلايا العصبية التي تُطلق إشاراتها معًا، تتصل معًا" - مثالًا على هذه العملية التعلّمية الموضعية.
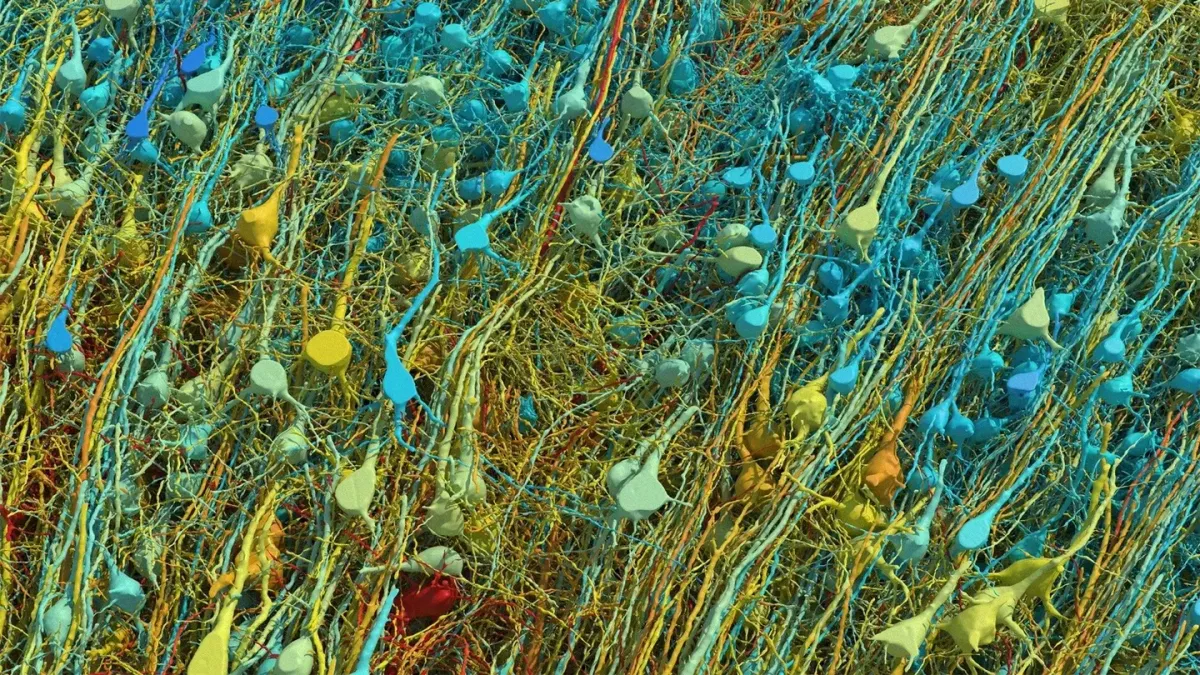
وبالمثل، فإن الدماغ البشري أقل ترابطًا بكثير من الشبكة العصبية الاصطناعية. فكل خلية عصبية من خلايا الدماغ البالغ عددها 86 مليارًا تتصل في المتوسط ببضعة آلاف فقط من الخلايا العصبية الأخرى.
ونتيجة لذلك، يمكن تخزين المعلومات بشكل معياري في مجموعات فرعية صغيرة من الخلايا العصبية دون التأثير على بقية الدماغ وتجنب خطر النسيان الكارثي.
ولنتأمل أنه في أي لحظة معينة - أثناء تعلم الشخص أو تفكيره أو قيامه بعمل ما - لا تتجاوز نسبة الخلايا العصبية النشطة في دماغه 1% إلى 10%، مقارنةً بنسبة 100% من الخلايا العصبية في نموذج التعلم العميق التقليدي.
(تعتبر بنى مزيج الخبراء المتفرقة ابتكارًا مهمًا وحديثًا في مجال الذكاء الاصطناعي على هذا الصعيد، لكنها لا تزال بعيدة كل البعد عن تفرق ونمطية الدماغ البشري).
وبالتالي فإن التباعد والنمطية هما مبدأان أساسيان في التصميم يمكّنان البشر من تحديث شبكاتهم العصبية باستمرار مع تجنب النسيان الكارثي.
سيكون من المفيد للغاية لو استطعنا تطبيق فهمنا لبنية الدماغ البشري المتفرقة والوحدانية لتطوير أنظمة ذكاء اصطناعي قادرة على التعلم المستمر.
ولكن لتحقيق ذلك، نحتاج أولاً إلى فهم الدماغ بشكل أعمق بكثير.
ما أوجه التشابه والاختلاف في بنية وسلوكيات الحصين والقشرة المخية التي تُمكّنهما من أداء دوريهما كمركزين للتعلم قصير المدى وطويل المدى؟
ما الذي يحدث تحديدًا في الدماغ أثناء النوم والأحلام والذي يُؤدي إلى ترسيخ التعلم بسلاسة؟ ما هي الآليات والعناصر البنائية الدقيقة التي تُتيح بنية الدماغ الموضعية والنمطية والمتفرقة؟
هذه أسئلة قابلة للإجابة، لكننا لا نملك الإجابات بعد. وللحصول عليها، نحتاج إلى استثمار أكبر بكثير في أبحاث الدماغ.
ضع في اعتبارك الاختبار التالي للذكاء الاصطناعي العام الذي اقترحه (AGI) رائد الذكاء الاصطناعي Andrew Ng في وقت سابق من هذا العام كنسخة محدثة من اختبار Turing الأصلي لعام 1950:
يُمنح الشخص الخاضع للاختبار - سواء كان حاسوبًا أو إنسانًا - إمكانية الوصول إلى حاسوب متصل بالإنترنت ومزود ببرامج مثل متصفح Web وبرنامج Zoom.
يصمم المُقيِّم تجربةً تمتد لعدة أيام للشخص الخاضع للاختبار، عبر الحاسوب، لأداء مهام وظيفية. على سبيل المثال، قد تتضمن التجربة فترة تدريب (كأن يكون موظفًا في مركز اتصال)، تليها مهمة تنفيذية (كالرد على المكالمات)، مع تلقي ملاحظات مستمرة.
يُحاكي هذا ما يُتوقع من عامل يعمل عن بُعد ولديه حاسوب يعمل بكامل طاقته (ولكن بدون كاميرا Web).
يجتاز الحاسوب اختبار تورينج للذكاء الاصطناعي العام إذا استطاع أداء المهمة الوظيفية بكفاءة تُضاهي كفاءة الإنسان الماهر.
لقد بلغ الحماس المُثار حول قرب ظهور الذكاء الاصطناعي العام حداً هائلاً؛ وللتأكد من ذلك، يكفي النظر إلى حسابات Twitter لأي موظف في شركة OpenAI. ومع ذلك، لا يستطيع أي نظام ذكاء اصطناعي اليوم اجتياز هذا الاختبار.
ونتوقع أنه بعد عام من الآن، سيبقى هذا الاختبار عصياً على الذكاء الاصطناعي.
ما السبب؟ لأن الذكاء الاصطناعي الحالي غير قادر بنيوياً على التعلم المستمر من التجارب والملاحظات.
وهذا قصور جوهري في الذكاء الاصطناعي اليوم يحد من تأثيره في العالم الحقيقي.
أما الدماغ البشري، من ناحية أخرى، فهو بارعٌ للغاية في القيام بذلك. لو فهمنا الدماغ بشكل أفضل، لأمكننا استعارة أسراره وتطويعها لبناء ذكاء اصطناعي أكثر قوة.
2. كفاءة استخدام الموارد
المجال التالي الذي يتمتع فيه الدماغ البشري بميزة هائلة على نماذج الذكاء الاصطناعي الحالية هو كفاءة استخدام الموارد.
من أبرز سمات الذكاء الاصطناعي الحديث احتياجاته الهائلة من الطاقة.
تم مؤخراً بناء العديد من مراكز بيانات الذكاء الاصطناعي التي تستهلك أكثر من 1 جيجاوات (GW) من الطاقة، أو هي قيد الإنشاء، بما في ذلك مشروع Rainier التابع لشركة Amazon في Indiana (2.2 جيجاوات)، و Colossus التابع لشركة xAI في Tennessee (2 جيجاوات)، و Hyperion التابع لشركة Meta في Louisiana (2 جيجاوات)، ومشروع Stargate Abilene التابع لشركة Oracle/ OpenAIفي تكساس (1.2 جيجاوات).
ولوضع هذه الأرقام في سياقها الصحيح، فإن 1 جيجاوات، أو 1 مليار واط، هو تقريبًا كمية الطاقة التي تستهلكها مدينة سان فرانسيسكو بأكملها .
وما زلنا في البداية. أعلن Sam Altman، الرئيس التنفيذي لشركة OpenAI، مؤخراً أن هدف OpenAI على المدى الطويل هو إضافة 1 جيجاوات جديد من سعة مراكز بيانات الذكاء الاصطناعي كل أسبوع.
يتطلب تدريب وتشغيل نماذج الذكاء الاصطناعي المتطورة اليوم كمية هائلة من الطاقة.
في الواقع، بدأت احتياجات الذكاء الاصطناعي الهائلة من الطاقة تصطدم بالفعل بحدود جميع مصادر الطاقة المتاحة على كوكب الأرض.
ولهذا السبب اكتسب وضع مراكز البيانات في الفضاء زخماً كبيراً مؤخراً، حيث وضع Elon Musk المفهوم كعنصر أساسي في عملية اندماج SpaceX/xAI والاكتتاب العام الأولي القادم لشركة SpaceX.
كما كتب Musk في فبراير: "لا يمكن تلبية الطلب العالمي على الكهرباء اللازمة للذكاء الاصطناعي بالحلول الأرضية، حتى على المدى القريب، دون التسبب في معاناة للمجتمعات والبيئة. وعلى المدى البعيد، من الواضح أن الذكاء الاصطناعي الفضائي هو السبيل الوحيد للتوسع."
لنقارن هذا الوضع بالدماغ البشري.
يزن دماغ الإنسان حوالي 3 أرطال. وهو موجود داخل جمجمتك. ويعمل بحوالي 20 واط من الطاقة.
20 واط. هذا أقل بمئة مليون مرة - ثمانية مراتب من حيث الحجم - من الطاقة التي يستهلكها مركز بيانات الذكاء الاصطناعي مثل Colossus من xAI أو Hyperion من Meta.
ومع ذلك، فإن الدماغ قادر على إنجازات معرفية لا تزال بعيدة المنال بالنسبة لأكثر تقنيات الذكاء الاصطناعي تطوراً اليوم.
كيف يُعقل هذا؟ كيف يتمكن الدماغ البشري من أن يكون أكثر كفاءة في استخدام الموارد من الذكاء الاصطناعي الحديث؟
باختصار، لا نعلم. ولو كنا نعلم، لكان ذلك مفتاحاً لتطوير أنظمة ذكاء اصطناعي أكثر كفاءة في استهلاك الطاقة، مما يفتح آفاقاً اقتصادية بمليارات الدولارات.
لكن لدينا بعض الأدلة المثيرة للاهتمام.
أولاً، الدماغ عبارة عن جهاز تناظري وليس حاسوبًا رقميًا. تُجبر الحواسيب الرقمية معالجة جميع المعلومات على أن تتم بخطوات منفصلة عالية الدقة ومُوقّتة، حيث تُقلب مليارات أو تريليونات البتات كل ثانية.
يتطلب إتمام عملية حسابية بسيطة مثل 5+5 على شريحة رقمية آلاف الخطوات لضمان تسجيل الإجابة بدقة 10.000000. كل خطوة من هذه الخطوات تستهلك طاقة.
في المقابل، في أجهزة الحوسبة التناظرية، تحدث عملية الحساب كنتيجة مباشرة للفيزياء والظواهر الفيزيائية، كما هو الحال في الدماغ، حيث تتحرك الأيونات داخل وخارج الخلايا العصبية.
تسمح الأجهزة التناظرية لفيزياء المكونات نفسها بإجراء العمليات الحسابية؛ فالحساب والعملية الفيزيائية هما شيء واحد.
ونتيجة لذلك، تتطلب أجهزة الكمبيوتر التناظرية طاقة أقل بكثير.
ثمة اختلاف معماري آخر بين أدمغة البشر وأجهزة الكمبيوتر الرقمية الحالية له تأثير كبير على كفاءة الطاقة، وهو التواجد المادي المشترك للحوسبة والذاكرة.
في أجهزة الذكاء الاصطناعي الحديثة، مثل وحدات معالجة الرسومات من Nividia، تُخزَّن أوزان نموذج الذكاء الاصطناعي في مكان واحد (ذاكرة الوصول العشوائي، أو RAM)، بينما تُنفَّذ أي عمليات حسابية تُجرى على هذه الأوزان في مكان آخر (معالج Tensor Core). عند تدريب نموذج الذكاء الاصطناعي أو نشره، يجب نقل أوزان النموذج باستمرار ذهابًا وإيابًا بين الذاكرة ومعالج Tensor Core.
تستهلك أنظمة الذكاء الاصطناعي اليوم نسبةً هائلةً من الطاقة، تصل الى 90%، لا لإجراء العمليات الحسابية، بل لنقل البيانات بين الذاكرة ووحدة المعالجة.
يُعرف هذا التحدي باسم " von Neumann bottleneck"، نسبةً إلى عالم الرياضيات الأسطوري John von Neumann الذي وضع في عام 1945 البنية الأساسية التي لا تزال تُشكّل أساس معظم الحواسيب الرقمية الحديثة.
هذه المشكلة غير موجودة في الدماغ البشري. لماذا؟ لأن نفس الوحدات الفيزيائية، وهي الخلايا العصبية في الدماغ، تخزن الذاكرة وتعالج المعلومات في آن واحد. بعبارة أخرى، معالجات الدماغ مصنوعة من الذاكرة.
تمثل كل هذه الملاحظات حول الدماغ تلميحات مثيرة للاهتمام حول كيفية بناء أجهزة وبرامج ذكاء اصطناعي أكثر كفاءة في استخدام الطاقة.
وبالفعل، تسعى العديد من شركات الذكاء الاصطناعي الرائدة اليوم إلى وضع خطط تكنولوجية مستوحاة من هذه الخصائص للدماغ البشري.
على سبيل المثال، كانت شركة Groq، المتخصصة في رقائق الذكاء الاصطناعي، رائدة في استخدام ذاكرة الوصول العشوائي الثابتة (SRAM) كوسيلة لدمج الذاكرة مع المعالجة فعليًا في تصميم الرقاقة.
ويؤدي تقليل المسافة بين الذاكرة والمعالجة إلى تقليل الحاجة إلى نقل البيانات، مما يخفف من اختناق von Neumann ويعزز كفاءة الطاقة. وقد استحوذت شركة Nvidia على Groq مقابل 20 مليار دولار قبل بضعة أشهر.
ومن الأمثلة الأخرى شركة Unconventional AI، وهي شركة ناشئة أطلقها مؤخراً رائد الأعمال الأسطوري في مجال الذكاء الاصطناعي Naveen Rao، بتمويل قدره 475 مليون دولار من شركات Sequoia وa16z وLightspeed. تسعى Unconventional إلى تطوير حاسوب تناظري يتميز بكفاءة طاقة أعلى بكثير من وحدات معالجة الرسومات الحالية، وذلك لتلبية احتياجات تطبيقات الذكاء الاصطناعي.
وكما قال Rao وفريقه : "للشبكات العصبية نظير بيولوجي بالفعل، وهو الدماغ البشري، الذي يستهلك 20 واطًا فقط. تستخدم الخلايا العصبية خصائصها الفيزيائية الكامنة لبناء الذكاء؛ ونحن نبني دوائر سيليكونية تُظهر ديناميكيات غير خطية مماثلة لبناء ركيزة جديدة للذكاء.
من خلال بناء التماثل الصحيح للذكاء، سنحقق مكاسب في الكفاءة بشكل أكثر فعالية من محاكاة هذه العمليات باستخدام حاسوب رقمي."
هذه جهودٌ واعدة، لكنها تستند إلى فهمٍ قاصرٍ وغير مكتملٍ للدماغ البشري. إذا أردنا بناء أنظمة ذكاء اصطناعي تضاهي كفاءة الدماغ البشري في استهلاك الطاقة - وهو إنجازٌ سيُحدث نقلةً نوعيةً في الحضارة - فإنّ أنجع السبل التي يُمكننا اتباعها هو الاستثمار في البحث العلمي لفهم آلية عمل الدماغ البشري بشكلٍ أفضل.
3. اكتشافات جديدة حقًا
تتعلم نماذج اللغة الضخمة اليوم عن العالم من خلال استيعاب كميات هائلة من البيانات الموجودة. وقد تم تدريب أنظمة الذكاء الاصطناعي مثل ChatGPT وClaude على كل ما كتبه البشر تقريبًا: الإنترنت بأكمله، وجميع كتب العالم، وجميع المقالات العلمية، وما إلى ذلك. وهذا يمكّنها من إجراء محادثات ذكية حول أي موضوع توجد عنه بالفعل مجموعة من المعارف.
لكن هذا يعني أيضاً أن قدراتها محددة ومحدودة بالمعرفة التي اكتشفها ونشرها البشر بالفعل. فعلى الرغم من القوة الهائلة التي تتمتع بها أنظمة الذكاء الاصطناعي اليوم، إلا أنها لا تزال عاجزة عن توليد معرفة جديدة غير موجودة أصلاً في بيانات تدريبها.
ولتأكيد هذه النقطة، دعونا ننظر في اختبار آخر للذكاء الاصطناعي العام اقترحه مؤخراً أحد أبرز خبراء الذكاء الاصطناعي.
قبل بضعة أشهر، طرحDemis Hassabis، الرئيس التنفيذي لشركة Google DeepMind، السؤال التالي: "النوع الذي أفكر فيه هو تدريب نظام ذكاء اصطناعي بمعرفة محدودة، على سبيل المثال، عام 1911، ثم معرفة ما إذا كان بإمكانه التوصل إلى النسبية العامة، كما فعل Einstein في عام 1915. أعتقد أن هذا هو نوع الاختبار الحقيقي لمعرفة ما إذا كان لدينا نظام ذكاء اصطناعي عام كامل."
لا يوجد نظام ذكاء اصطناعي في العالم اليوم قادر على فعل أي شيء قريب من هذا.
الشيء الوحيد في الكون المعروف الذي أنتج معرفة جديدة صافية هو الدماغ البشري. نظرية نيوتن للجاذبية الكونية، ونظرية باستور للجراثيم، ونظرية داروين للتطور عن طريق الانتقاء الطبيعي، ونظرية ميكانيكا الكم، وفلسفة نيتشه الأخلاقية الثورية: هذه بعض الأمثلة التاريخية الأكثر إثارة للدهشة على قدرة العقل البشري على تحقيق قفزة نوعية، وتوليد رؤية ثاقبة غير مسبوقة، وإعادة صياغة كيفية عمل العالم بطريقة تقطع جوهرياً مع الماضي.
كل ما يشكل الحضارة الحديثة - المباني التي نسكنها، والملابس التي نرتديها، والسيارات والطائرات التي نسافر بها، والأدوية التي نتناولها، والمدن التي نعيش فيها، والأجهزة والشبكات الرقمية التي نستخدمها للتواصل - لا وجود له إلا بسبب عدد لا يحصى من هذه القفزات وإعادة التصورات، بعضها كبير وبعضها صغير، تراكمت على مدى آلاف السنين من النشاط البشري.
في الواقع، يمكن القول إن خلق المعرفة الجديدة هو أهم قدرة للدماغ البشري، وهي السمة المميزة لذكائنا العام.
وهي قدرة لا تزال بعيدة المنال بالنسبة للذكاء الاصطناعي الحالي.
إن للدماغ البشري دروساً أو دروساً قليلة ليعلمنا إياها في سعينا نحو الذكاء الاصطناعي العام، حقاً!
يجدر بنا هنا أن نذكر كلمة عن التعلم المعزز.
بخلاف نماذج المحولات ذاتية الانحدار، التي تدعم نماذج التعلم الخطي، فإن التعلم المعزز هو نموذج ذكاء اصطناعي لا يستلزم التعلم من البيانات الموجودة التي أنشأها الإنسان.
بدلاً من ذلك، يعمل التعلم المعزز من خلال وضع وكيل ذكاء اصطناعي في بيئة تفاعلية والسماح له بالتعلم بنفسه عبر التجربة والخطأ.
فبينما يختبر الوكيل بشكل مباشر الإجراءات التي تؤدي إلى نتائج إيجابية وتلك التي تؤدي إلى نتائج سلبية، يتعلم تدريجياً كيفية التنقل بفعالية في العالم لتحقيق أهدافه.
يمكن للتعلم المعزز أن يُنتج سلوكيات ذكية ومتطورة بشكل مذهل في أنظمة الذكاء الاصطناعي، وهذه السلوكيات أحيانًا لا تشبه إطلاقًا ما يفعله البشر أو ما فعلوه سابقًا في موقف معين.
ولأنها لا تُدرَّب على بيانات بشرية موجودة مسبقًا ولا تُعلَّم تقليد البشر، فإن الأنظمة القائمة على التعلم المعزز تُظهر أحيانًا ابتكارًا وإبداعًا حقيقيين.
ولعل المثال الأكثر شهرة على ذلك هو "الخطوة 37"، من مشروع AlphaGo التابع لشركة DeepMind.
لعبة غو الصينية القديمة هي أكثر ألعاب الطاولة تعقيدًا في العالم، فهي أكثر تعقيدًا بكثير من الشطرنج، إذ تحتوي على عدد من الوضعيات القانونية على رقعة اللعب يفوق عدد الذرات في الكون.
لطالما ساد الاعتقاد باستحالة بناء ذكاء اصطناعي قادر على هزيمة أفضل لاعب بشري في لعبة غو، أو على الأقل أن مثل هذا الذكاء الاصطناعي سيظل بعيد المنال لعقود طويلة.
ثم في عام 2016، صدمت شركة DeepMind العالم عندما كشفت النقاب عن AlphaGo، وهو نظام ذكاء اصطناعي للعب لعبة Go، والذي هزم أفضل لاعب Go بشري في العالم، لي سيدول، في مباراة من خمس جولات.
وجاءت اللحظة الأكثر تميزاً في المباراة مع النقلة رقم 37 التي قام بها برنامج ألفا غو في المباراة الثانية.
كانت نقلة Alpha غو رقم 37 غريبة، لدرجة أن العديد من المراقبين افترضوا أنها خطأ. لقد تناقضت بشكل مباشر مع آلاف السنين من الحكمة البشرية المتراكمة حول كيفية لعب غو. كانت غير متوقعة لدرجة أن سيدول اضطر إلى النهوض ومغادرة الغرفة لمدة 15 دقيقة ليستجمع قواه.
أثبتت النقلة رقم 37 أنها خطوة استراتيجية رائعة وغير مسبوقة. لقد كانت نقطة التحول التي أدت إلى فوز Alpha غو الحاسم في المباراة الثانية وفي المباراة ككل.
قال Sedol لاحقًا: "إنها ليست حركة بشرية. لم أرَ قط إنسانًا يلعب هذه الحركة... إنها رائعة. كنت أظن أن برنامج ألفا غو يعتمد على حساب الاحتمالات وأنه مجرد آلة. لكن عندما رأيت هذه الحركة، غيرت رأيي. بالتأكيد، Alpha غو مبدع."
إذن: هل نموذج التعلم المعزز، الذي تم توضيحه بشكل واضح من خلال الخطوة 37، يقوض الفرضية القائلة بأن أنظمة الذكاء الاصطناعي الحالية غير قادرة على توليد معرفة جديدة بالطريقة التي يستطيع بها الدماغ البشري القيام بذلك؟
بعض التأملات.
أولًا، على الرغم من أن برنامج AlphaGo كان إنجازًا مذهلًا لشركة DeepMind، إلا أنه من المهم أن نتذكر أنه مجرد لعبة لوحية.
تتكون لوحة لعبة Go من شبكة مربعة 19×19 مع نوعين من القطع (السوداء والبيضاء). تُعد الألعاب اللوحية بيئات مبسطة ومحدودة للغاية مقارنةً بالعالم الحقيقي.
لم نشهد حتى الآن أي إنجازٍ مدفوعٍ بالتعلم المعزز يتمتع بالابتكار والإبداع اللذين تميزت بهما "الخطوة 37" في أي مجالٍ من مجالات العالم الحقيقي، كالفيزياء أو الأحياء أو الاقتصاد.
إن اليوم الذي نشهد فيه تطبيق "الخطوة 37 في العالم الحقيقي" سيكون علامةً فارقةً في التاريخ.
لكن النقطة الأهم هنا هي أن الدماغ يبدو بالفعل وكأنه يقوم بنوع من التعلم المعزز، ويبدو أن هذا يلعب دورًا رئيسيًا في تمكين قدراته المعرفية الفريدة.
على سبيل المثال، في عام 2020، اكتشف فريق من DeepMind وجامعة هارفارد أن خوارزمية تُعرف باسم التعلم المعزز للفرق الزمني التوزيعي، والتي تم استخدامها بنجاح لسنوات في الشبكات العصبية الاصطناعية، تُستخدم في الواقع أيضًا كخوارزمية بواسطة الدماغ البشري، حيث يلعب الناقل العصبي الدوبامين دورًا رئيسيًا في تنفيذ الخوارزمية.
كما كتب الباحثون : "إن وجود التعلم المعزز التوزيعي في الدماغ له آثار مثيرة للاهتمام على كل من الذكاء الاصطناعي وعلم الأعصاب.
هذا الاكتشاف يمنحنا ثقة أكبر بأن أبحاث الذكاء الاصطناعي تسير في الاتجاه الصحيح، حيث أن هذه الخوارزمية تُستخدم بالفعل في أكثر الكيانات ذكاءً التي نعرفها: الدماغ."
نتفق مع باحثي DeepMind وجامعة هارفارد على أن حقيقة استخدام الدماغ البشري للتعلم المعزز هي دليل مقنع على أن التعلم المعزز سيلعب دورًا رئيسيًا في الطريق إلى الذكاء الاصطناعي العام.
ومع ذلك: فإن معظم خوارزميات التعلم المعزز المستخدمة في مجال الذكاء الاصطناعي اليوم لا تزال بسيطة وغير فعالة من نواحٍ عديدة.
قال Andrej Karpathy، القائد السابق للذكاء الاصطناعي في شركتي Tesla وOpenAI، بصراحة: "إن التعلم المعزز اليوم أسوأ بكثير مما يعتقده الشخص العادي. التعلم المعزز سيء للغاية. كل ما كان لدينا سابقًا أسوأ بكثير لأننا كنا في السابق نقلد البشر فحسب."
من بين الانتقادات الأخرى، وصف Karpathy بشكل لا يُنسى التعلم المعزز اليوم بأنه "يمتص الإشراف من خلال قشة" - مما يعني باختصار أن خوارزميات التعلم المعزز اليوم لا تزال خشنة وغير فعالة لأنها لا تستطيع استخلاص سوى إشارة أساسية (مكافأة إيجابية أو سلبية) من مجموعات معقدة وطويلة وغنية بالمعلومات من الإجراءات.
يبدو أن الدماغ البشري يُشغّل نسخةً أكثر أناقةً وتطوراً من التعلم المعزز مقارنةً بما توصل إليه باحثو الذكاء الاصطناعي الرائدون اليوم.
إذا استطعنا معرفة ماهيتها - إذا استطعنا فهم كيفية عمل الدماغ بشكل أفضل - فقد يكون ذلك مفتاحاً لابتكار ذكاء اصطناعي قادر على تحقيق اكتشافات ورؤى جديدة.
خاتمة
"إن الدماغ البشري هو المثال الوحيد الذي لدينا على وجود ذكاء عام في الكون، على حد علمنا"، هذا ما قاله مؤخراً Demis Hassabis، الرئيس التنفيذي والمؤسس المشارك لشركة Google DeepMind.
وتابعت Hassabis، الحاصلة على درجة الدكتوراه في علم الأعصاب الإدراكي، شرحها قائلة: "لهذا السبب درست علم الأعصاب، لأنني أردت أن أفهم نقطة البيانات الوحيدة التي لدينا والتي تثبت أن هذا ممكن".
والجدير بالذكر أن Dario Amodei، الرئيس التنفيذي والمؤسس المشارك لشركة neuroscience، حاصل أيضاً على درجة الدكتوراه في علم الأعصاب.
وكما قال أمودي مؤخراً: "اتجهتُ في الأصل إلى علم الأعصاب لأني أردتُ فهم كيفية عمل الذكاء على مستوى أساسي".
إن فرص التعاون والتفاعل بين مجالي علم الأعصاب والذكاء الاصطناعي هائلة، لكنها لا تزال غير مستكشفة بشكل كافٍ وغير مستثمر فيها حتى اليوم.
وبغض النظر عن حقيقة أن البنية الأساسية لأنظمة الذكاء الاصطناعي الحالية - الشبكات العصبية - مستوحاة بشكل فضفاض من الأدمغة البيولوجية، فإن فهمنا للدماغ البشري لا يلعب دورًا كبيرًا في توجيه أبحاث الذكاء الاصطناعي الرائدة اليوم.
هذا أمر مؤسف وفرصة ضائعة.
إنها نتيجة، قبل كل شيء، لحقيقة أننا ببساطة لا نفهم كيف يعمل الدماغ البشري بشكل جيد بما يكفي لكي نستفيد منه بشكل مباشر في كيفية بناء أنظمة الذكاء الاصطناعي.
لكن بإمكاننا تغيير هذا. بإمكاننا، بل يجب علينا، أن نجعل من تحقيق فهم أعمق للدماغ البشري أولوية ملحة للغاية.
إنّ الكشف عن الخوارزميات والبنى التفصيلية الموجودة داخل أدمغتنا سيمكننا من تطوير أنظمة ذكاء اصطناعي من الجيل التالي قادرة على التعلم المستمر، وتستهلك طاقة أقل بكثير، وقادرة على تحقيق اكتشافات جديدة جوهرية.
ستتجاوز قيمة هذه الأنظمة قيمة أنظمة الذكاء الاصطناعي الحالية بكثير. سيكون هذا هو الهدف الأسمى.
عندما نتحدث عن استثمار المزيد من الموارد لفهم الدماغ البشري بشكل أفضل، فماذا نعني تحديداً؟ وما هي المبادرات الأكثر جدوى؟
هناك العديد من الأمثلة، لكننا سنسلط الضوء على مثال واحد على وجه الخصوص: رسم خريطة الاتصال العصبي البشري .
يشير مصطلح " connectome" إلى خريطة شاملة لكيفية اتصال جميع الخلايا العصبية والتشابكات العصبية في الدماغ ببعضها البعض. إنه مخطط توصيلات كهربائية للدماغ، خليةً تلو الأخرى.
إن امتلاك مخطط الاتصال البشري سيمكن من فهم أعمق وأكثر تحديدًا وأكثر اكتمالًا وأكثر قابلية للتنفيذ لكيفية بناء الدماغ وكيفية عمله.
لفهم الدور التحويلي الذي يمكن أن يلعبه المخطط العصبي في علم وتكنولوجيا الذكاء، ربما يكون أفضل مثال تاريخي هو مشروع الجينوم البشري وتأثيره على التكنولوجيا الحيوية.
قال البروفيسور Sebastian Seung، أستاذ جامعة Princeton ورائد علم الاتصال العصبي: "يمثل الاتصال العصبي في مجال تكنولوجيا الأعصاب ما كان يمثله الجينوم في مجال التكنولوجيا الحيوية.
اليوم، هناك ضجة كبيرة حول إمكانات تكنولوجيا الأعصاب في استعادة وظائف الدماغ البشري وتعزيزها.
لكن تكنولوجيا الأعصاب لن تحقق كامل إمكاناتها بدون الاتصال العصبي. لولا تحوّل التكنولوجيا الحيوية إلى صناعة تبلغ قيمتها تريليونات الدولارات بفضل مشروع Genome البشري والثورة الجينومية، لكانت بقيت سوقًا متخصصة.
وفي خضم ذلك، سيتحول الذكاء البيولوجي، وهو أكثر الألغاز غموضًا، بفضل علم الاتصال العصبي إلى تقنية مفتوحة المصدر. وستتضح مبادئ تصميمه، مما يتيح نهجًا جديدًا ومثيرًا للاتصال العصبي في مجال الذكاء الاصطناعي."
يُعدّ رسم خرائط الاتصالات العصبية تحديًا هندسيًا معقدًا ويستغرق وقتًا طويلًا. لكن ليس من الضروري التسرع في السعي إلى رسم خريطة كاملة للاتصالات العصبية البشرية، لأن هناك خطوات وسيطة قيّمة على طول الطريق.
في عام ١٩٨٦، أنجز الباحثون رسم خريطة الاتصال العصبي لدودة C. elegans (التي تضم ٣٠٢ عصبونًا) ، لتكون بذلك أول خريطة اتصال عصبي حيوانية تُرسَم على الإطلاق. وجاء الإنجاز الكبير التالي في علم الاتصال العصبي في أواخر عام ٢٠٢٤، عندما أعلن فريق من الباحثين بقيادة Seung عن رسم خريطة الاتصال العصبي لذبابة الفاكهة Drosophila (التي تضم ١٣٩٢٥٥ عصبونًا). وقد أسهمت هاتان الخريطتان بشكل كبير في تعزيز فهمنا لكيفية عمل أدمغة الحيوانات.
تتمثل أفضل خطوة تالية في رسم خريطة أول اتصال عصبي للثدييات، على الأرجح فأر (حوالي 85 مليون خلية عصبية) - حيث يتشابه دماغ الفأر ودماغ الإنسان بنسبة 99٪ من الناحية الجينية، لذلك سنتعلم الكثير من اتصال الفأر - قبل الانتقال إلى الهدف النهائي المتمثل في الاتصال العصبي البشري (حوالي 86 مليار خلية عصبية).
كم ستكون التكلفة؟
تختلف التقديرات، لأن تكاليف التقنيات المستخدمة لإنتاج مخططات الاتصال العصبي تتراجع بسرعة وهي هدف متحرك.
يقدر Adam Marblestone، الرئيس التنفيذي لشركة Convergent Research وأحد المفكرين البارزين في مجال علم الأعصاب والذكاء الاصطناعي، أنه يمكننا تحقيق مخطط كامل لشبكة الاتصال العصبي للفأر بأقل من 100 مليون دولار.
تتراوح التقديرات الخاصة بمخطط الاتصال البشري الكامل عموماً في حدود عشرات المليارات من الدولارات، إن لم يكن أقل.
هذا مبلغ ضخم، لكن لكشف أسرار الذكاء العام الوحيد في الكون المعروف وفهمها، سيكون استثمارًا مجديًا. إنه جزء ضئيل من رأس المال الذي يُنفق على مراكز بيانات الذكاء الاصطناعي سنويًا، وسيُغطي تكلفته أضعافًا مضاعفة.
من الصعب تخيل مشروع علمي أكثر جدوى للاستثمار فيه.








